-
Produkt
 Produktfunksjoner
ProduktfunksjonerBransjeledende AI, datafangst på linjenivå, lettvint PO-mathcing, godkjenning på farten og mye mer.
 Datafangst
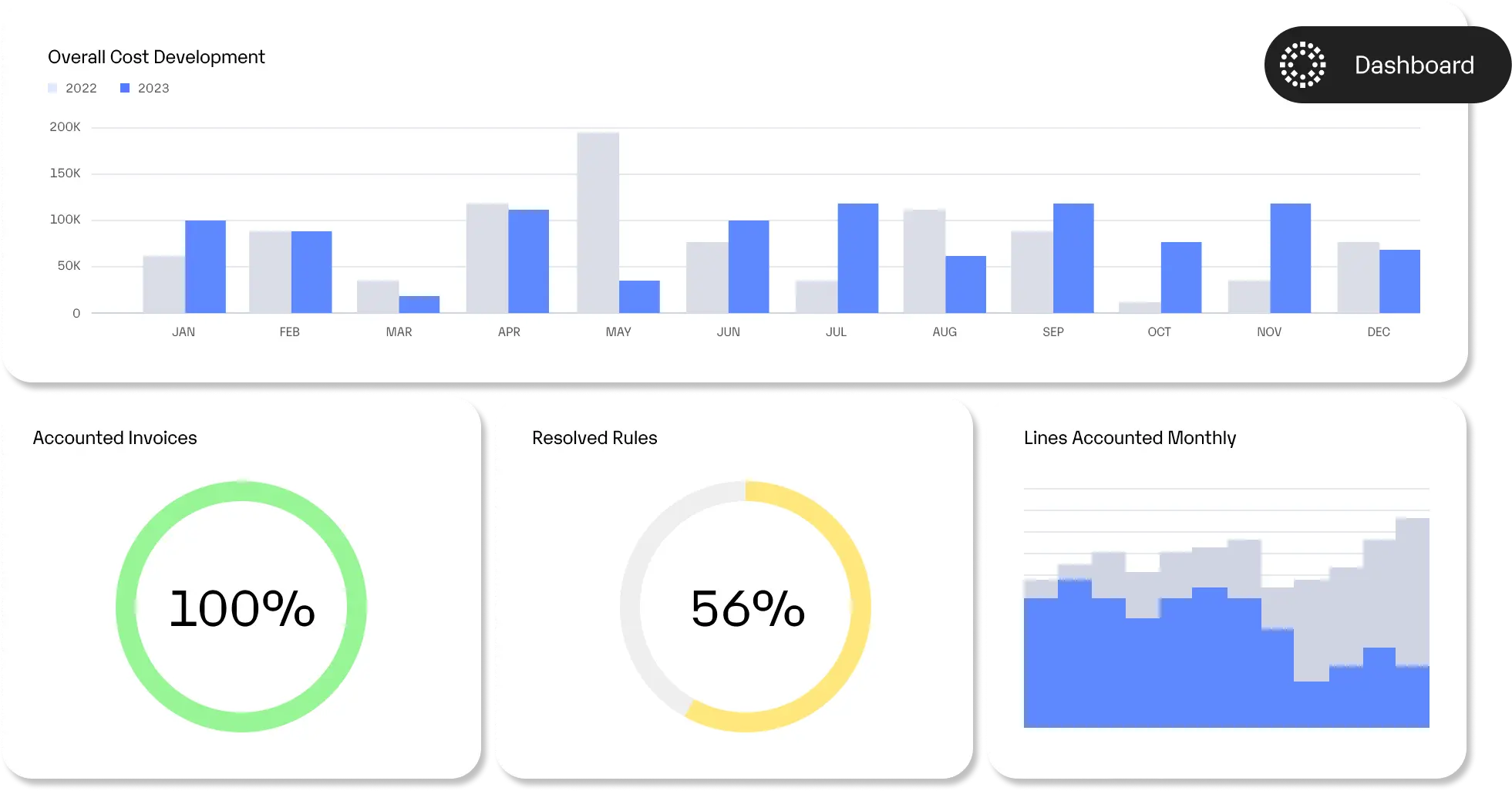
DatafangstSEMINE fanger opp data både fra hode- og linjenivå, innkjøpsordre og annet – nøyaktig og helt automatisk.
-
Løsninger
 Regnskapsbyråer
RegnskapsbyråerStrømlinjeformet automatisering på tvers av selskaper og porteføljer, bidrar til fullstendig fleksibilitet, frigjøring av ressurser og ny innsikt.
 Eiendomsbransjen
EiendomsbransjenFelles oversikt over alle bygg og selskaper i et brukergrensesnitt. Automatisk påføring av all konteringsinformasjon.
 Entreprenører
EntreprenørerBruk mer tid på leverandør- og prosjektoppfølging, og mindre tid på håndtering av inngående fakturaer.
 Shared Service Centre
Shared Service CentreStrømlinjeformede og automatiserte prosesser styrker forretningsresultatene. Få mer innsikt, høyere kvalitet og øk effektiviteten i alle enheter.
 Hotell- og servicebransjen
Hotell- og servicebransjenProsessoptimalisering med automasjon på linjenivå, dimensjonsfangst, automatisk periodisering og godkjenning av fakturaer på farten.
 Energisektoren
EnergisektorenMed automatisk innsamling av relevante data oppnår dere større åpenhet, bedre oversikt, kostnadsbesparelser, økt synlighet og hundre prosent nøyaktighet.
 Detaljhandel
DetaljhandelGjør arbeidsmengden mer håndterlig, få en komplett oversikt over virksomhetens økonomi, forhandle frem bedre avtaler og identifiser mulige områder for besparelser.
 Prosessoptimalisering
ProsessoptimaliseringSEMINE forenkler komplekse og sammensatte prosesser knyttet til inngående fakturahåndtering, og muliggjør no-touch regnskapsføring.
 Digitalisering
DigitaliseringSEMINE transformerer og forbedrer regnskapsprosessene i din virksomhet, fra manuell og papirbasert til automatisert og digitalisert.
 Virksomhetsstyring
VirksomhetsstyringBruk dybdeinnsikt fra datafangst på fakturalinjenivå til å ta smartere og bedre forretningsavgjørelser.
 Økonomisjef
ØkonomisjefSEMINE effektiviserer økonomi- og regnskapsavdelingen, hever kvaliteten på interne leveranser, og styrker beslutningsevnen.
 Regnskapsleder
RegnskapslederVår automasjonsløsning gir ditt team verktøyene for å automatisere repetitive oppgaver, slik at de kan fokusere på andre mer verdiøkende oppgaver.
- Ressurser
- Selskap
- Partnere
- Kontakt
- Logg inn
.webp)